DataFrame/Series에서 집계함수를 사용할수있습니다. 데이터베이스의 집계함수와 비슷하다고 접근하면 이해에 도움이 됩니다.
Aggregation 함수를 수행할때 axis를 명시하지 않으면 axis=0이 기본값으로 설정됩니다. 보통 axis=1인 행방향 계산은 많이 안한다고합니다. 그래도 기억하기!-!
Group By
DataFrame의 groupby()인자로 컬럼명을 입력하면 입력된 컬럼명을 기반으로 groupby라는 중간집합을 만들어 줍니다. → DataFrameGroupBy 객체를 반환합니다.
이렇게 반환된 객체에 aggregation 함수를 수행합니다.
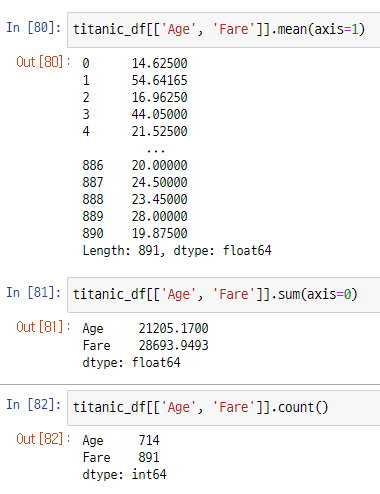
- axis = 1 은 모든 행에 대해서 집계 함수를 수행하기때문에 length가 데이터의 row길이 임을 확인할 수 있습니다.
- count 함수는 null값을 카운트 하지 않기 때문에 titanic_df의 row개수보다 적게 나온것입니다.

- DataFrameGroupBy객체는 groupby()가 수행된 컬럼명이 인덱스로 나타납니다. 여기서는 Pclass를 groupby의 파라미터로 주었기 때문에 Pclass가 인덱스로 나타납니다.

- Pclass 컬럼 groupby를 수행하고 반환된 DataFrameGroupBy객체에서 특정 컬럼으로 필터링을 한뒤 count와 같은 aggregation를 수행할 수 있습니다.
- titanic_df[['Pclass','PassengerId', 'Survived']].groupby('Pclass').count() 명령어도 동일한 결과를 보장합니다.
특정 열의 값들만 count해서 보고싶을때는? titanic_df['Pclass'].value_counts()
'AI > Machine Learning' 카테고리의 다른 글
| [파이썬 머신러닝 완벽 가이드 정리] 2. 사이킷런으로 시작하는 머신러닝 - #1 붓꽃 품종 예측 (0) | 2021.02.28 |
|---|---|
| [파이썬 머신러닝 완벽 가이드 정리] 1. 파이썬 기반의 머신러닝과 생태계 이해 - #3 Pandas (0) | 2021.02.13 |
| [파이썬 머신러닝 완벽 가이드 정리] 1. 파이썬 기반의 머신러닝과 생태계 이해 - #2 Numpy (0) | 2021.02.12 |
| [파이썬 머신러닝 완벽 가이드 정리] 1. 파이썬 기반의 머신러닝과 생태계 이해 - #1 (0) | 2021.02.12 |


